Introduction
The COSMOROE Search Engine is a text-based search engine for multimedia documents. It has been designed as a support tool for COSMOROE (CrOSs-Media inteRactiOn rElations), a framework for modelling multimedia dialectics, i.e. the semantic interplay between images, language and body movements. COSMOROE defines a number of semantic relations between different modalities, for formulating multimedia messages (see Figure 1 and more details in papers in the Documentation section).
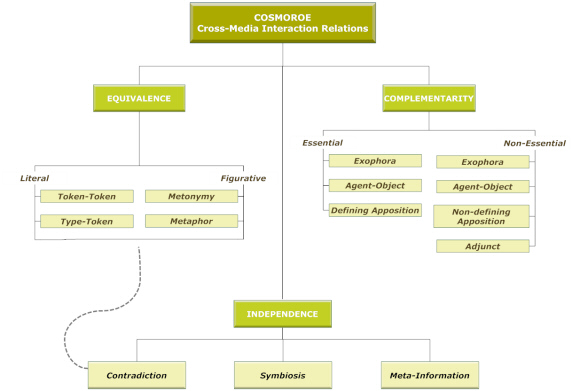
Currently, the COSMOROE Search Engine indexes and retrieves information from audiovisual files, manually processed for transcribing speech and text (e.g. subtitles, scene text, graphic text), identifying visual objects of interest, body movements and gestures of interest or even whole frame sequences of interest, labelling this visual content and annotating the COSMOROE relations in which they participate. However, the ultimate objective is to use this search engine with data that will be augmented with such metadata automatically.
The engine allows one to:
- perform a simple text-based search, taking advantage of the COSMOROE relations -behind the scenes- for more precise and intelligent retrieval within multimedia archives, and
- perform an advanced text-based search, filtering the query with criteria that are directly related to multimedia semantics and to multi-modal relations specific information.
In both cases, functionalities related to the sorting of the results, result presentation to the user and exploration of the contents of the underlying database, in the form of quantified profiles of the data and its relational conceptual presentations are provided.
The following sections, provide more details on all these aspects of the system.
Simple Search
From the "Simple Search" page the user can type the query of interest, in a straightforward manner, like in any text-based search engine. The keyword or keywords entered are searched among the multimedia files stored in a database. Figure 2 presents a simple example of keyword search. (For more information about keyword typing methods see Section Typing Conventions).
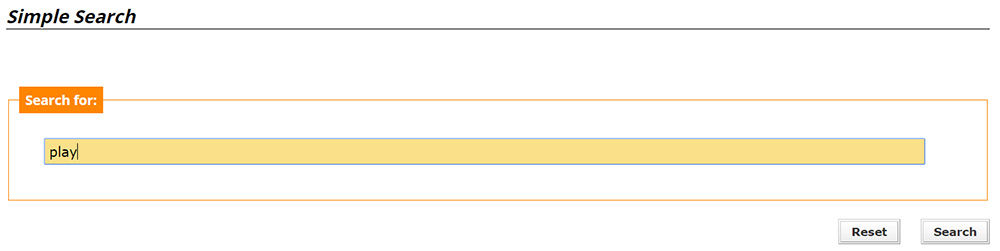
The meaning of the query is, as expected: Search for multimedia files that contain the word play, in the transcribed text or in the labelled visual content.
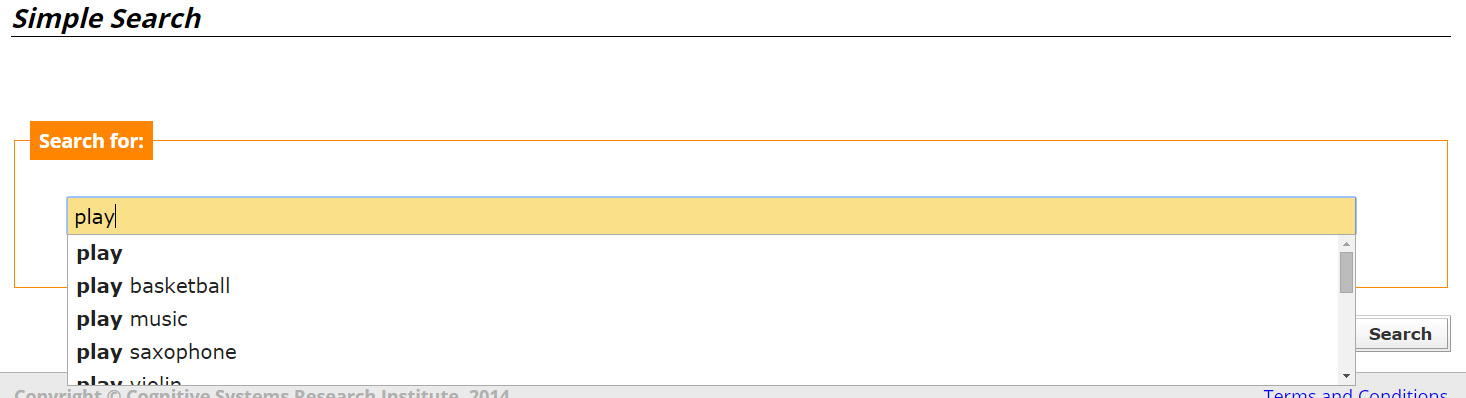
Also, as the user starts typing a search word, a list of the matching terms currently found on the database, is shown below the input field, as shown in Figure 3. Multiple search terms can be selected by clicking on each of them.
Typing Conventions
The user should pay special attention to certain conventions, used for keyword typing, in order to avoid error messages and achieve better retrieval results.
- English keywords are used to retrieve English multimedia files.
- Greek keywords are used to retrieve Greek multimedia files.
- Keywords are case insensitive.
- Using an asterisk (*) at the end of a keyword enables prefix term search.
- Typing more than one terms in each query box is possible. Use a comma character, prefixed and suffixed with a space character in order to separate the different search terms.
- Multiple terms in a query box are searched for using a disjunctive logic.
Advanced Search
In the "Advanced Search" page the user is presented with the possible options that (s)he can set and consequently formulate the query. The page mainly consists of three sections, see Figure 4, each one devoted to the alternative ways with which the user may query the content of the multi-modal relations.
- Section 1 ("Search by Argument Combination") roughly corresponds to the classical keyword entry method, with two separate query fields, one for each argument participating in a relation.
- Section 2 ("Search by Modality Combination") corresponds to the specificities of each argument, depending on its modality and can either filter the terms entered, or used independently, in order to search for an argument of a relation, based on its type.
- Section 3 ("Search by Multimodal Relation Type") offers the user the option of searching for specific COSMOROE relations.
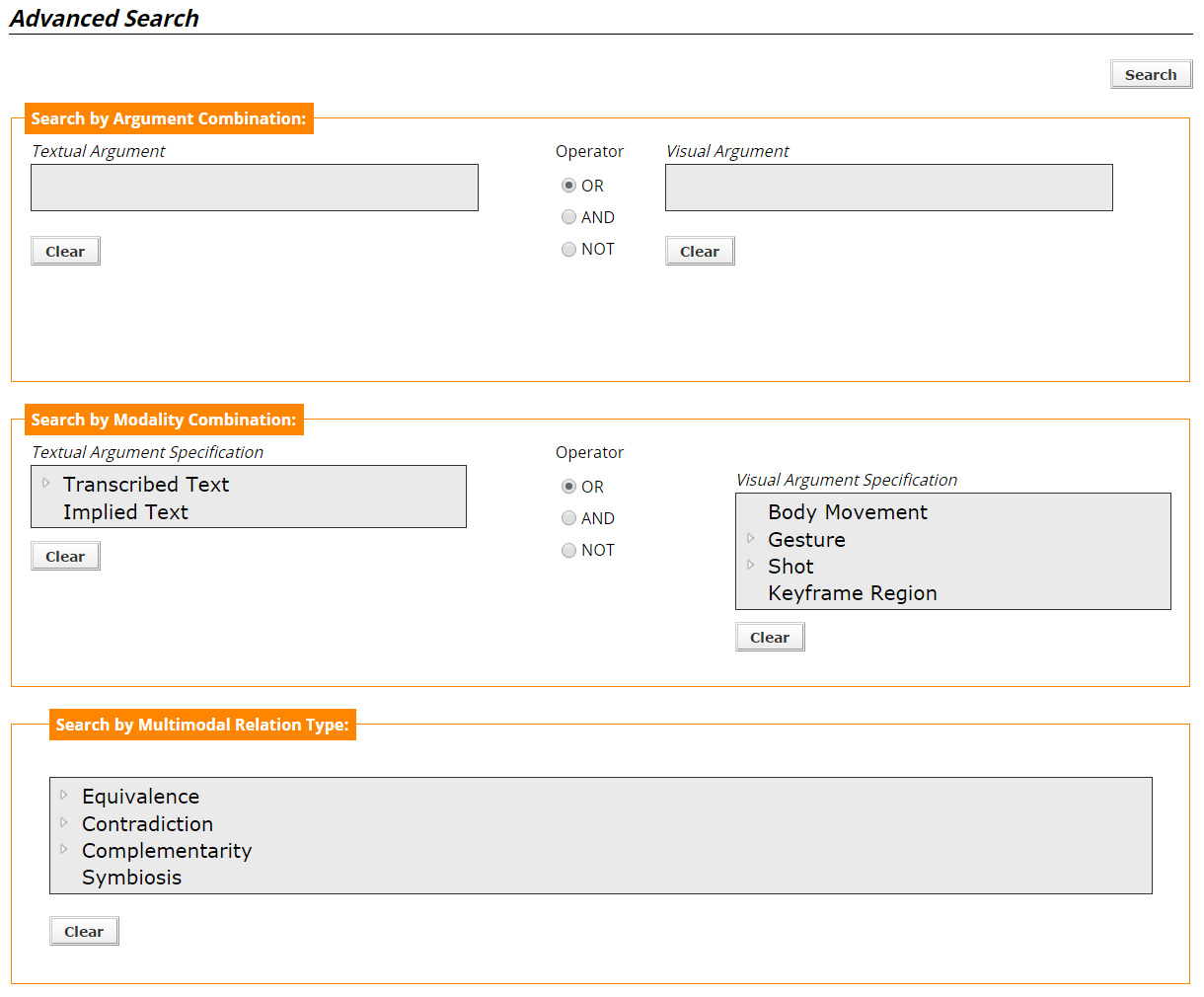
Each section can be used either separately or in conjunction with the others. That means that the user is free to define suitable search criteria, filling any one from the three sections, or all of them. In case multiple sections are filled, their criteria are combined using a conjunctive approach ("AND" links).
Search by Argument Combination
The top section of the Advanced Search page, gives the user the possibility to search for either of the arguments participating in a multimodal relation (see Figure 5). Specifically, (s)he can search for the Textual Argument and/or the Visual Argument, i.e. for something said and/or something seen in a multimedia video.
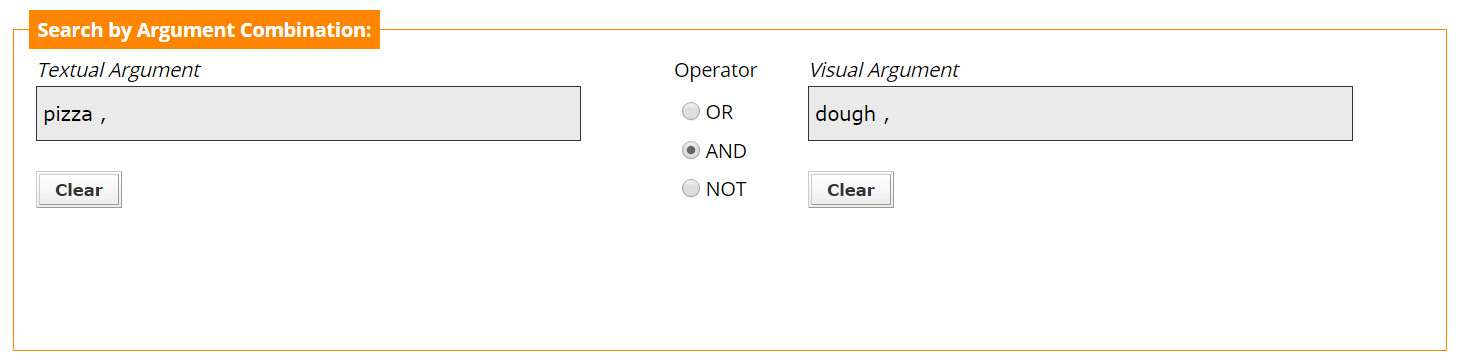
Figure 5 shows an example of searching for a combination of a textual and a visual argument. The meaning of this query is: Search for a multimedia file where someone says the word pizza, while some dough is shown in the video.
Like in the Simple Search, as soon as the user starts typing, a list of suggested terms appears, which in this case are different for each argument, since the terms appearing as textual arguments of a relation are not the same as the visual argument terms.
Operators
While the "Textual" and "Visual" arguments can be used separately, with the user filling either of the two forms, there is also the possibility of searching for a combination of them, by filling both forms and using the operators "OR", "AND", "NOT", for logically combining them.
The operator in the middle, defines the way the two arguments will be logically connected, in order to formulate the final query.
- OR: equals to the boolean operator "or", signifying the logical disjunction
- AND: equals to the boolean operator "and", signifying the logical conjunction
- NOT: equals to the boolean operator "not", signifying the logical negation of the second query
Search by Modality Combination
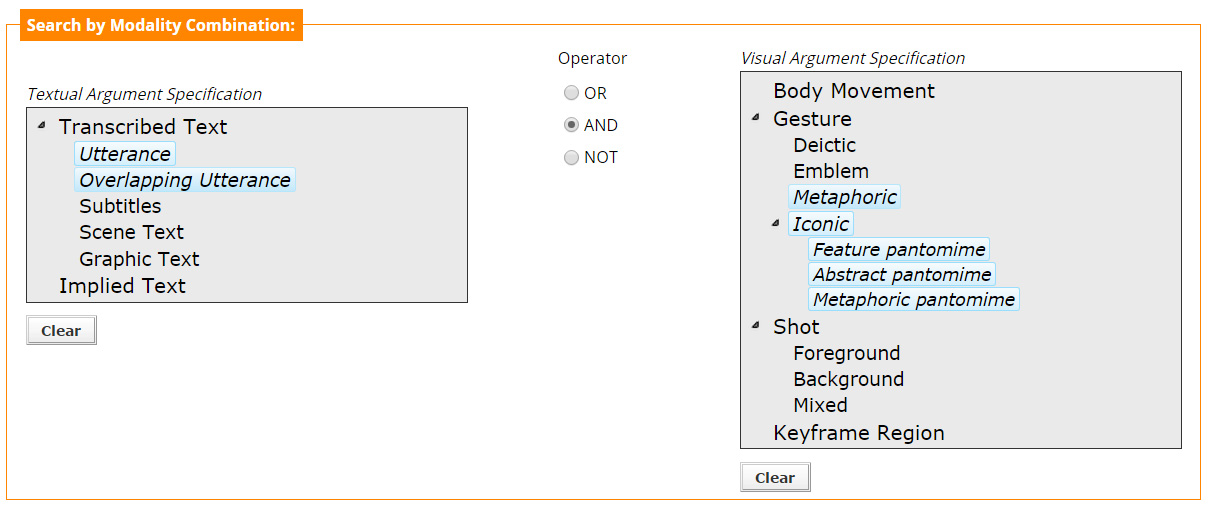
The middle section of the Advanced Search page, gives the user the possibility to search for either of the arguments participating in a multimodal relation not by defining their content, but rather by defining their type (see Figure 6).
Textual Argument
Through the "Textual Argument Specification" part of the search interface, the user can search for any word or phrase that has been said ("Utterance" or "Overlapping Utterance" or "Subtitles"), or any text that can be seen on the video ("Scene Text" or "Graphic Text"), or any text that is implied but not specifically expressed in any modality ("Implied Text"), but which is necessary for linking the two arguments (for a more in-depth explanation see Implied Relations section). All these choices are possible through selecting one or more of the provided choices, as seen in Figure 6. In this example, the user selected to search for any word or phrase that has been said, by selecting the types "Utterance" and "Overlapping Utterance".
The options for the specification of the type of the textual argument are hierarchically structured. It can be seen that there are two major categories, the Transcribed Text and the Implied Text. The first choice is further divided in 5 possible subcategories, namely Utterance, Overlapping Utterance, Subtitles, Scene Text, and Graphic Text.
Multiple selection of categories and subcategories is possible by simply clicking on the desired options, while by clicking again on an option this becomes deselected. By clicking on a category that has subcategories, all options are automatically selected. Multiple selected options are matched disjunctively.
Visual Element
Similarly to the "Textual Argument Specification", through the "Visual Argument Specification" part of the search interface, the user can search for something shown on the multimedia file that has been annotated and labelled. Specifically, the user can search for a body movement, a gesture, a frame sequence (shot) or a keyframe region. All these choices are possible through clicking any of the choices seen in Figure 6. In this case, the user selected to see any of the metaphoric or iconic gestures that can be seen in the video.
As in the case of the "Textual Argument", the options for the specification of the type of the visual argument are hierarchically structured. There are four major categories, the Body Movement, the Gesture, the Shot and the Keyframe Region. The second choice has 4 subcategories, defining the type of gesture, while the third choice has 3 subcategories defining which part of the shot is of interest.
Multiple hierarchical selection is also possible, with multiple selected options being matched disjunctively.
Operators
Like in the "Argument combination section" the user can use the operators to combine the different types of arguments. For example, in Figure 6 the user will actually search for any text said ("Utterance" or "Overlapping Utterance"), while at the same time a "Metaphoric" or "Iconic" Gesture is shown in the video.
Search by Multimodal Relation Type
An alternative way of searching through the multimedia files is by defining a specific type of relation. This is implemented at the "Search by Multimodal Relation Type" section, where the user can select the type or types of relation that combine the textual and visual arguments found in a multimedia file.
Such an example is given in Figure 7, where the user is searching for all the Token-Type (Literal Equivalence) relations, for all the Metonymy (Figurative Contradiction) relations and all the Non Essential (Complementarity) relations.
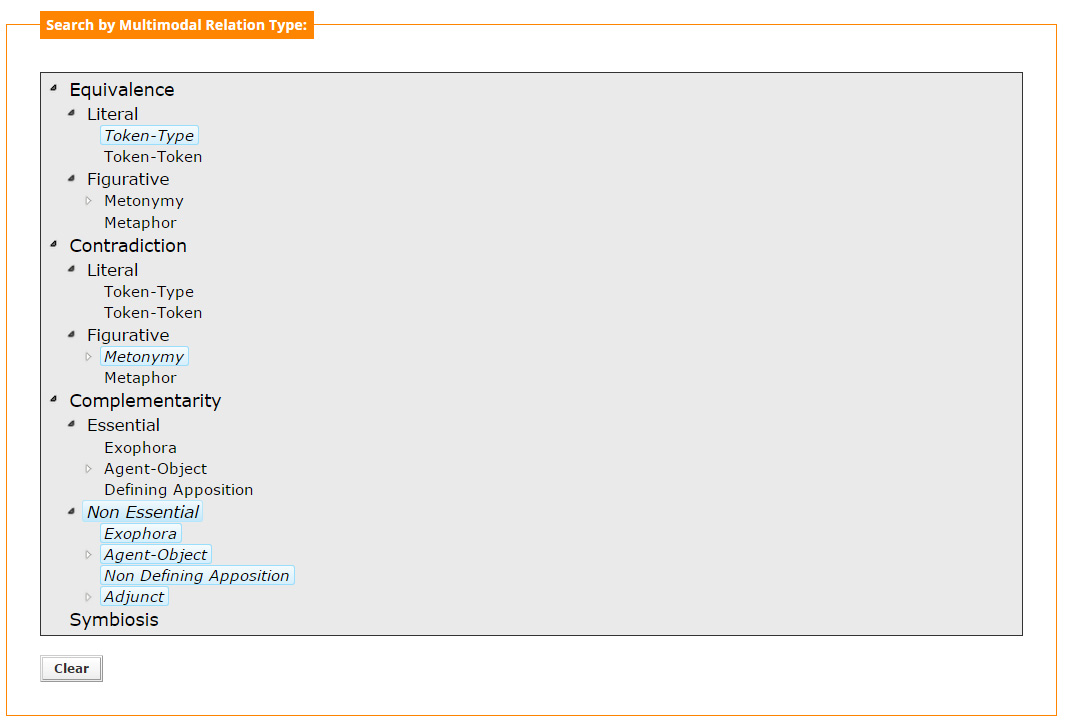
As in the cases of the "Textual" and "Visual" argument specification, multiple hierarchical selection of the types of relations is also possible. Again, by selecting an upper category, all the subcategories are automatically selected, whereas multiple selected options are being matched disjunctively. Note that categories and subcategories preceded with an arrow are expandable.
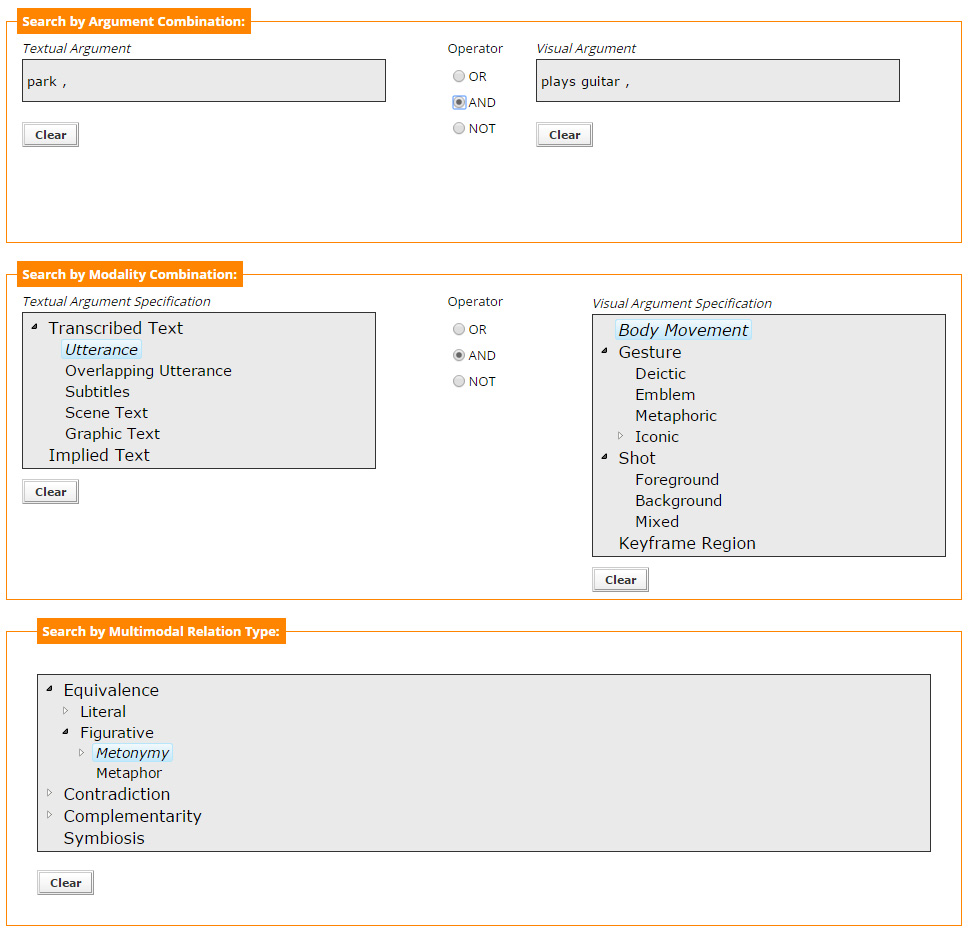
Search by Argument, Modality and Relation Type
By combining all sections in the Advanced Search page, the user can search by the most "specific" way, for a textual argument and a visual argument, found participating in a specific relation. For example, Figure 8 shows the following query: Search for mulitmedia files that contain the word park uttered by someone and the label "plays quitar" denoting a body movement, with those two arguments found in a Metonymy (Figurative Equivalence) relation.
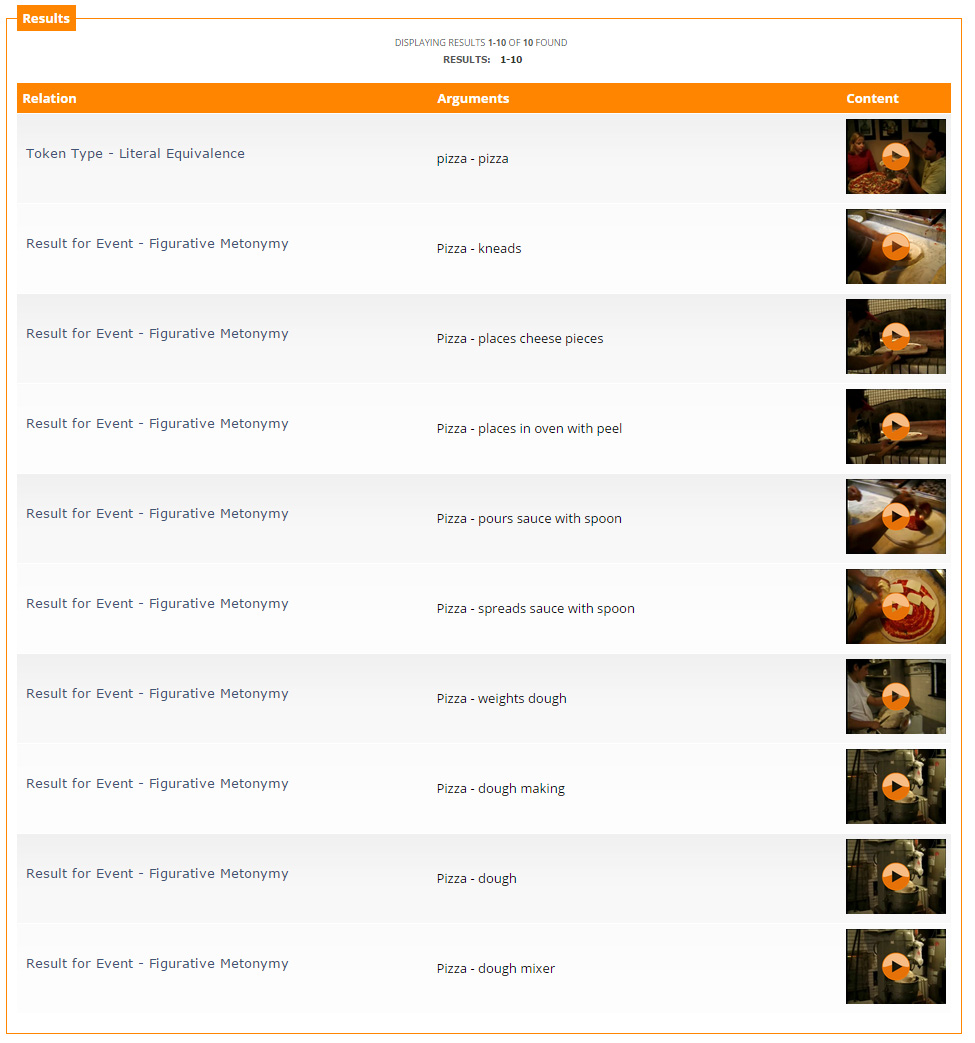
Results
In the "Results Page" the user can see the multimedia files that matched the given query, along with the arguments accompanying each relation and a hyperlink to the section of the video file that contains the relation. Figure 9 presents such an example page.
On the left, the type of the relation found is shown, In the middle column, the arguments of the relation are presented, so the user can quickly get an idea of the content of the relation and on the right column there is a link that opens a new window showing the part of the video itself. Similarly, the left column opens a new window, which contains more information for each result found.
One can notice that among the results there are elements that do not belong to any relation. These are labelled as "Element not in a relation" and usually are elements of the video, either textual or visual, that have been annotated for mulitmodal retrieval purposes.
An indication of the number of results found is given at the top. Results are sorted according to a modified version of a classical tf/idf score, based on a multifaceted search field scheme. Exact matches of a given query are ranked higher than partial matches. The results are then sorted according to the type of the relation, with those characterised as "Equivalence" being first, followed by "Complementarity" relations and "Symbiosis", while the "Elements not in a relation" are last.
Relation View
By accessing an individual result, the "Relation View Page" opens, where all the components of the relation are presented, as seen in Figure 10.
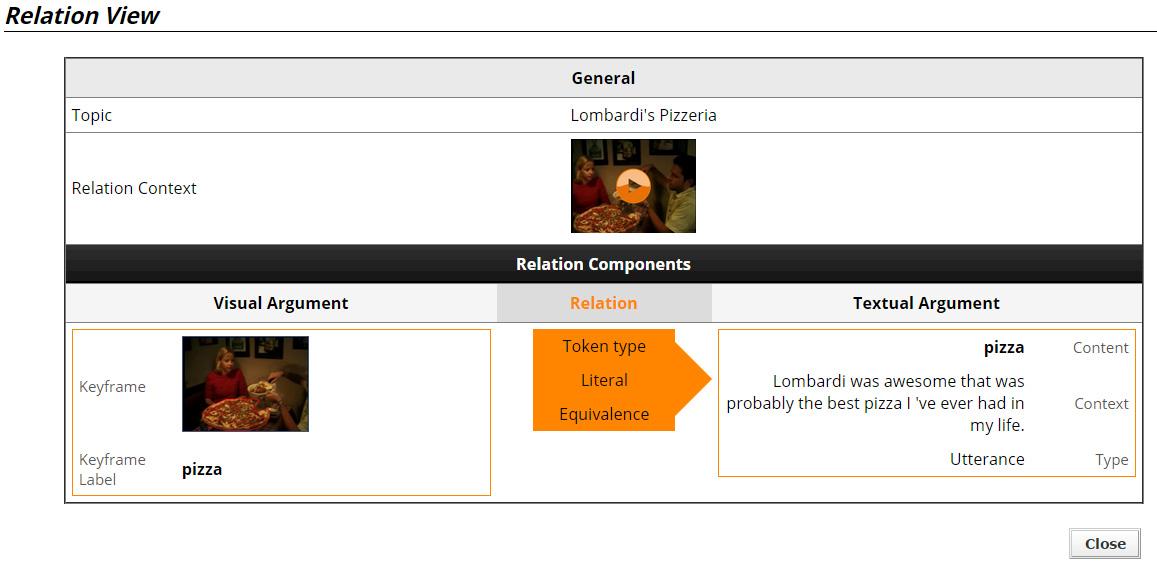
Depicted here are the textual and visual arguments of the relation and information about the type of the relation connecting the two arguments. The user can also watch the video clip "containing" the whole relation, or the video clips of the modalities that participate in it and see static images of specific objects, with the objects' contour highlighted. Mouse over the keyframe image maximizes the image for a clearer view.
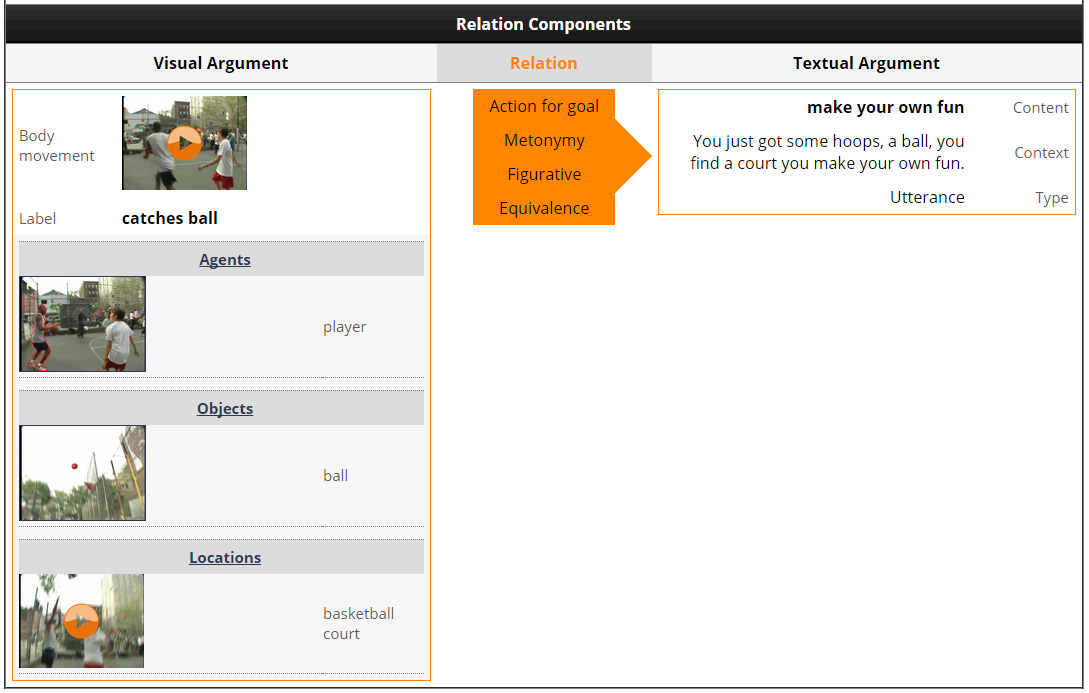
Body movements and Gestures
When the visual argument is a body movement or a gesture, it is not just the argument itself that is depicted (its annotation label and its corresponding video clip), but also its complements, namely the agent, the tool, the affected object and the location of the action, following the principles of the minimalist grammar of action (see Documentation section). For example, Figure 11 shows the body movement labelled as "catches ball", with three of its complements annotated. Initially the complements are not expanded (only their general category is shown). Figure 12 shows the body movement with all the complements unfolded. The user can have a more detailed view, either seeing an annotated keyframe of the complement, or watching a video clip.

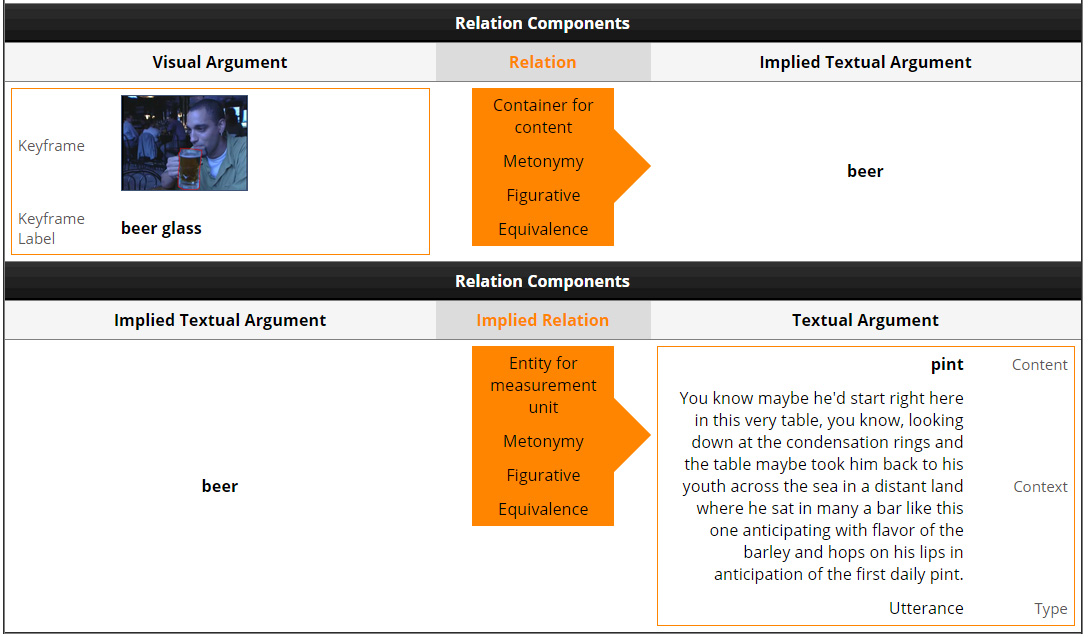
Implied Relations
In some cases, the two arguments of the relation are not directly connected, but an additional argument, not explicitly said or shown, is needed. This implied argument creates an implied relation, which is necessary for correctly relating the visual and textual arguments. Such an example is shown in Figure 13. Here, the visual argument is "beer glass" and the textual argument is "pint", for which no direct relation exists. Adding the implied argument "beer", a chain of two relations is created and the visual and textual arguments are now related through the given relational sequence.
Technical Specification
In developing the COSMOROE search interface, specific application needs had to be taken into consideration. The main goal was to develop a text-based search engine module, capable of handling files in the .xml format and accessed by local and remote users. The core implementation is actually a web application, mainly based on the Apache Lucene search engine library.
This choice is supported by Lucene's intrinsic characteristics, such as high-performance indexing and searching, scalability and customization options and open source, cross-platform implementation, that render it one of the most suitable solutions for text-based search.
Documentation
- Pastra K. (2015), "COSMOROE Annotation Guide", CSRI Technical Report Series, CSRI-TRS-150201, Cognitive Systems Research Institute, ISSN 2407-9952. [pdf]
- Pastra K., Balta E. (2009), "A text-based search interface for Multimedia Dialectics", in Proceedings of the System Demonstration Session of the 12th Conference of the European Association for Computational Linguistics, pp. 53-56, Athens, Greece. [pdf]
- Pastra K. (2008), "COSMOROE: A Cross-Media Relations Framework for Modelling Multimedia Dialectics", Multimedia Systems, vol. 14 (5), pp. 299-323, Springer Verlag. [pdf]
- Pastra K., Balta E., Dimitrakis P., Bandavanou E., and Lada M. (2009), "Image-Language Dialectics in Greek Caricatures", I. Latsis Foundation, Research Studies 2009 (monograph in Greek). [pdf] [youtube video]
- Pastra K. and Aloimonos Y. (2012), "The Minimalist Grammar of Action", Philosophical Transactions of the Royal Society B, 367(1585):103.
- Zlatintsi A., Koutras P., Evangelopoulos G., Malandrakis N., Efthymiou N., Pastra K., Potamianos A., and Maragos, Petros (2017), "COGNIMUSE: a multimodal video database annotated with saliency, events. semantics, and emotion with application to summarization", EURASIP Journal on Image and Video Processing.
- Zlatintsi A., Koutras P., Efthymiou N., Maragos P., Potamianos A., and Pastra K. (2015), "Quality Evaluation of Computational Models for Movie Summarization", in Proc. 7th Int'l. Workshop on Quality of Multimedia Experience (QoMEX-2015), Costa Navarino, Messinia, Greece, May 2015.